|
Curso de iniciación a la programación con C# |
CONTROL DE FLUJO: ESTRUCTURAS ITERATIVAS
Pasamos ahora a un nuevo conjunto de instrucciones de mucha utilidad. En realidad, casi todos los lenguajes cuentan con instrucciones parecidas (si no iguales) o que funcionan de un modo muy similar a las que vamos a ver aquí. Las estructuras iterativas de control de flujo se ocupan de repetir una serie de líneas de código tantas veces como el programador indique o bien hasta que se de una cierta condición. A estas estructuras también se les llama bucles.
Aquellos de vosotros que conozcáis otros lenguajes veréis que todos estos bucles se parecen mucho a los que ya conocéis. Los que os estéis iniciando ahora en la programación puede que tardéis un poco en hallar la utilidad de todo esto: ¿para qué vamos a hacer que el programa repita varias veces el mismo código? Bueno, de momento os diré que en todo programa, al igual que los bloques if y los bloques switch, los bucles son también el pan nuestro de cada día, así que no tardaréis en acostumbraros a ellos.
BUCLES FOR
Los bucles for van asignando valores a una variable desde un valor inicial hasta un valor final, y cuando la variable contiene un valor que está fuera del intervalo el bucle termina. Veamos la sintaxis para hacernos mejor a la idea:
for (var=inicial;condición;siguientevalor)
{
Instrucciones
}
Sé que esto es algo difícil de leer, incluso para aquellos que hayan programado en otros lenguajes, puesto que los bucles for de C no se parecen mucho, en cuanto a su sintaxis, al resto de los bucles for de los otros lenguajes, así que trataré de explicarlo con detenimiento. Como veis, tras la sentencia for se indican las especificaciones del bucle entre paréntesis. Dichas especificaciones están divididas en tres partes separadas por punto y coma: la parte de asignación del valor inicial en primer lugar; la parte que verifica la continuidad del bucle (mediante una condición) en segundo lugar; y la parte en que se calcula el siguiente valor en tercer lugar. Pongamos un ejemplo: vamos a calcular el factorial de un número dado, que se encuentra almacenado en la variable num. Se podría hacer de dos formas:
for (byte i=num; i>1 ; i--)
{
fact*=i;
}
O bien:
for (byte i=1; i<=num ; i++)
{
fact*=i;
}
Claro, para que esto funcione, la variable fact ha de valer 1 antes de que el programa comience a ejecutar el bucle. Bien, veamos ahora cómo se van ejecutando estas instrucciones paso a paso:
|
1º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
2º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
3º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
|
4º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
5º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
6º paso:
for (byte i=num; i>1 ; i--) { fact*=i; } |
En primer lugar se asigna a la variable i el valor de num (vamos a suponer que num vale 3), es decir, después del primer paso, el valor de i es 3. Posteriormente se comprueba si dicha variable es mayor que 1, es decir, si 3>1. Como la condición del segundo paso se cumple se ejecuta el código del bucle en el tercer paso, fact*=i, con lo que fact (que valía 1) ahora vale 3 (1*3). En el cuarto paso se asigna el siguiente valor a i (i--), con lo que, ahora, i valdrá 2. En el quinto se vuelve a comprobar si i es mayor que 1, y como esto se cumple, el sexto paso vuelve a ejecutar el código del bucle (de nuevo, fact*=i), con lo que ahora fact vale 6 (3*2). El séptimo paso es idéntico al cuarto, es decir, se asigna el siguiente valor a la variable i (de nuevo, i--), con lo que ahora i valdría 1. El octavo paso es idéntico al quinto, comprobando por lo tanto si i es mayor que 1. Sin embargo esta vez, la condición no se cumple (1 no es mayor que 1, sino igual), por lo que la ejecución saldría del bucle y ejecutaría la siguiente línea del programa que esté fuera de él. Date cuenta de que el bucle se seguirá ejecutando siempre que la condición ( i>1 ) se cumpla, y dejará de ejecutarse cuando la condición no se cumpla. Por lo tanto, no habría sido válido poner i==2 en lugar de i>1, ya que esta condición se cumpliría únicamente cuando num valiera 2, pero no en cualquier otro caso. ¿Serías capaz de ver cómo funcionaría el otro bucle? Venga, inténtalo.
BUCLES FOR ANIDADOS
Efectivamente, se pueden colocar bucles for dentro de otros bucles for, con lo que obtendríamos lo que se llaman los bucles for anidados. Son también muy útiles: por ejemplo, piensa que tienes almacenadas unas cuantas facturas en una base de datos, y quieres leerlas todas para presentarlas en pantalla. El problema está en que cada factura tiene una o varias líneas de detalle. ¿Cómo podríamos hacer para cargar cada factura con todas sus líneas de detalle? Pues usando bucles anidados. Colocaríamos un bucle for para cargar las facturas, y otro bucle for dentro de él para que se cargaran las líneas de detalle de cada factura. Así, el segundo bucle se ejecutará completo en cada iteración del primer bucle. Veamos un ejemplo que nos aclare todo esto un poco más:
using System;
namespace BuclesAnidados
{
class BuclesAnidadosApp
{
static void Main()
{
for (int i=1; i<=3; i++)
{
Console.WriteLine("Factura número {0}", i);
Console.WriteLine("Detalles de la factura");
for (int j=1; j<=3; j++)
{
Console.WriteLine(" Línea de detalle {0}", j);
}
Console.WriteLine();
}
string a=Console.ReadLine();
}
}
}
Como ves, el bucle "j" está dentro del bucle "i", de modo que se ejecutará completo tantas veces como se itere el bucle i. Por este motivo, la salida en consola sería la siguiente:
Factura número 1
Detalles de la factura
Línea de detalle 1
Línea de detalle 2
Línea de detalle 3
Factura número 2
Detalles de la factura
Línea de detalle 1
Línea de detalle 2
Línea de detalle 3
Factura número 3
Detalles de la factura
Línea de detalle 1
Línea de detalle 2
Línea de detalle 3
¿Sigues sin verlo claro? Bueno, veamos cómo se van ejecutando estos bucles:
|
1º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
2º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
3º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
|
4º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
5º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
6º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
|
7º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
8º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
9º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
|
10º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
11º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
12º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
|
13º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
14º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
15º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
|
16º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
17º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
18º paso:
for (int i=1; i<=3; i++) { for (int j=1; j<=3; j++) { ... } } |
El decimonoveno paso sería igual que el sexto, el vigésimo igual que el séptimo, y así hasta terminar el bucle i. Bueno, donde están los puntos suspensivos estaría el código que forma parte del bucle j. Como ves, el segundo bucle (el bucle j) se ejecuta completo para cada valor que toma la variable i del primero de los bucles. Vete haciendo el cálculo mental de cuánto van valiendo las variables para que lo veas claro. Por supuesto, se pueden anidar tantos bucles como sea necesario.
BUCLES WHILE
Bien, para los que no sepan inglés, "while" significa "mientras", de modo que ya os podéis hacer la idea: un bucle while se repetirá mientras una condición determinada se cumpla, o sea, devuelva true. Veamos su sintaxis:
while (expresión bool)
{
Instrucciones
}
Efectivamente, las "Instrucciones" que se hallen dentro del bucle while se ejecutarán continuamente mientras la expresión de tipo boolean retorne true. Por ejemplo, podemos escribir un bucle while para pedir una contraseña de usuario. Algo así:
using System;
namespace BuclesWhile
{
class BuclesWhileApp
{
static void Main()
{
string Clave="Compadre, cómprame un coco";
string Res="";
while (Res!=Clave)
{
Console.Write("Dame la clave: ");
Res=Console.ReadLine();
}
Console.WriteLine("La clave es correcta");
string a=Console.ReadLine();
}
}
}
En este pequeño ejemplo el programa pedirá una y otra vez la clave al usuario, y cuando este teclee la clave correcta será cuando finalice la ejecución del mismo. Así, la salida en la consola de este programa sería algo como esto (en rojo está lo que se ha tecleado durante su ejecución):
Dame la clave: No quiero
Dame la clave: Que no
Dame la clave: eres contumaz, ¿eh?
Dame la clave: Vaaaaale
Dame la clave: Compadre, cómprame un coco
La clave es correcta
¿Alguna pregunta? ¿Que qué habría pasado si la condición no se hubiera cumplido antes de ejecutar el bucle, es decir, si Res ya contuviera lo mismo que Clave antes de llegar al while? Bien, pues, en ese caso, el bucle no se hubiera ejecutado ninguna vez, es decir, al comprobar que la expresión de tipo boolean retorna false, la ejecución del programa pasa a la primera línea que se encuentra a continuación del bucle. Vamos a verlo para que te quede más claro. Modificaremos ligeramente el ejemplo anterior, así:
using System;
namespace BuclesWhile
{
class BuclesWhileApp
{
static void Main()
{
string Clave="Compadre, cómprame un coco";
string Res=Clave;
while (Res!=Clave)
{
Console.Write("Dame la clave: ");
Res=Console.ReadLine();
}
Console.WriteLine("La clave es correcta");
string a=Console.ReadLine();
}
}
}
En efecto, en este caso, la salida en consola sería la siguiente:
La clave es correcta
Ya que la ejecución no pasa por el bucle. Bueno, ya veis que es muy sencillo. Por cierto, luego os propondré algunos ejercicios para que practiquéis un poco todo esto de los bucles (a ver si pensabais que os ibais a escaquear).
BUCLES DO
Ciertamente, estos bucles tienen mucho que ver con los bucles while. La diferencia es que estos se ejecutan siempre al menos una vez, mientras que los bucles while, como acabamos de ver antes, pueden no ejecutarse ninguna vez. Veamos la sintaxis de los bucles "do":
do
{
Instrucciones
} while (expresión bool);
Como ves, también hay un while y una expresión boolean, pero en este caso se encuentra al final. De este modo, la ejecución pasará siempre por las instrucciones del bucle una vez antes de evaluar dicha expresión. Vamos a rehacer el ejemplo anterior cambiando el bucle while por un bucle do:
using System;
namespace BuclesDo
{
class BuclesDoApp
{
static void Main()
{
string Clave="Compadre, cómprame un coco";
string Res="";
do
{
Console.Write("Dame la clave: ");
Res=Console.ReadLine();
} while (Res!=Clave);
Console.WriteLine("La clave es correcta");
string a=Console.ReadLine();
}
}
}
El resultado sería el mismo que antes. La diferencia está en que aquí daría exactamente lo mismo lo que valiera la variable Res antes de llegar al bucle, puesto que este se va a ejecutar antes de comprobar dicho valor, y al ejecutarse, el valor de Res se sustituye por lo que se introduzca en la consola. Por lo tanto, repito, los bucles do se ejecutan siempre al menos una vez.
Por otro lado tenemos otro tipo de bucle, los bucles foreach, pero no hablaremos de ellos hasta que hayamos visto arrays e indizadores. Tened un poco de paciencia, que todo se andará.
INSTRUCCIONES DE SALTO
No es que vaya a salirnos un tirinene en la pantalla dando brincos como un poseso, no. Las instrucciones de salto permiten modificar también el flujo del programa, forzando la siguiente iteración de un bucle antes de tiempo, o la salida del mismo o bien mandando la ejecución directamente a un punto determinado del programa (esto último está altamente perseguido y penado por la ley, o sea, los jefes de proyecto). Son pocas y muy sencillas, así que podéis estar tranquilos, que no os voy a soltar otra biblia con esto...
LA INSTRUCCIÓN BREAK
Algo hemos visto ya sobre la instrucción break. ¿Cómo que no? Anda, repásate la entrega anterior, hombre... Mira que se te ha olvidado pronto... En fin... a lo que vamos. La instrucción break fuerza la salida de un bucle antes de tiempo o bien de una estructura de control de flujo condicional en la que se encuentre (un switch). Ahora nos fijaremos en los bucles, que es donde andamos. Pondremos un ejemplo sencillo: El siguiente programa escribirá múltiplos de 5 hasta llegar a 100:
using System;
namespace InstruccionBreak
{
class InstruccionBreakApp
{
static void Main()
{
int num=0;
while (true)
{
Console.WriteLine(num);
num+=5;
if (num>100) break;
}
string a=Console.ReadLine();
}
}
}
¿Qué es eso de while (true)? Pues un bucle infinito. ¿No decíamos que dentro de los paréntesis había que colocar una expresión boolean? Pues entonces... true es una expresión boolean. De este modo, el bucle es infinito (claro, true siempre es true). Sin embargo, cuando la variable num tiene un valor mayor que 100 la ejecución del bucle terminará, pues se ejecuta una instrucción break.
LA INSTRUCCIÓN CONTINUE
La instrucción continue fuerza la siguiente iteración del bucle donde se encuentre (que puede ser un bucle for, while, do o foreach). Como esto se ve muy bien con un ejemplo, vamos con ello: El siguiente programa mostrará todos los números del uno al veinte a excepción de los múltiplos de tres:
using System;
namespace InstruccionContinue
{
class InstruccionContinueApp
{
static void Main()
{
for (int i=1; i<=20; i++)
{
if (i % 3 == 0) continue;
Console.WriteLine(i);
}
string a=Console.ReadLine();
}
}
}
En este ejemplo, el bucle for va asgnando valores a la variable i entre 1 y 20. Sin embargo, cuando el valor de i es tres o múltiplo de tres (es decir, cuando el resto de la división entre i y 3 es cero) se ejecuta una instrucción continue, de modo que se fuerza una nueva iteración del bucle sin que se haya escrito el valor de i en la consola. Por este motivo, aparecerían todos los números del uno al veinte a excepción de los múltiplos de tres.
"ER MARDITO GOTO"
Sí, C# mantiene vivo al "maldito goto". Si te digo la verdad, el goto, aparte de ser el principal baluarte de la "programación des-estructurada", es un maestro de la supervivencia... de lo contrario no se explicaría que siguiera vivo. En fin... Trataré de explicaros cómo funciona sin dejarme llevar por mis sentimientos... De momento te diré que goto hace que la ejecución del programa salte hacia el punto que se le indique. Simple y llanamente. Luego te pongo ejemplos, pero antes quiero contarte alguna cosilla sobre esta polémica instrucción.
Según tengo entendido, la discusión sobre mantener o no el goto dentro del lenguaje C# fue bastante importante. Puede que alguno se esté preguntando por qué. Veamos: la primera polémica sobre el goto surgió cuando se empezaba a hablar de la programación estructurada, allá por finales de los 60 (hay que ver, yo aún no había nacido). Si alguno ha leído algún programa escrito por un "aficionado" al goto sabrá perfectamente a qué me refiero: esos programas son como la caja de pandora, puesto que no sabes nunca qué puede pasar cuando hagas un cambio aparentemente insignificante, ya que no tienes modo se saber a qué otras partes del programa afectará ese cambio.
En realidad, el problema no es la instrucción goto en sí misma, sino el uso inadecuado que algunos programadores le dan (pocos, gracias a Dios). Ciertamente, hay ocasiones en las que una instrucción goto hace la lectura de un programa mucho más fácil y natural. ¿Recordáis de la entrega anterior el ejemplo en el que había un switch en el que nos interesaba que se ejecutaran el caso 2 y el caso 3? Lo habíamos resuelto con un if, de este modo:
switch (opcion)
{
case 1:
descuento=10;
break;
case 2:
case 3:
if (opcion==2) regalo="Cargador de CD";
descuento=5;
break;
default:
descuento=0;
break;
}
En este ejemplo, si opción valía 2 se asignaba una cadena a la variable regalo y, además se asignaba 5 a la variable descuento. Pues bien, en este caso un goto habría resultado mucho más natural, intuitivo y fácil de leer. Veámoslo:
switch (opcion)
{
case 1:
descuento=10;
break;
case 2:
regalo="Cargador de CD";
goto case 3;
case 3:
descuento=5;
break;
default:
descuento=0;
break;
}
Como veis, hemos resuelto el problema anterior de un modo mucho más natural que antes, sin tener que usar una sentencia if. Veamos ahora un ejemplo de cómo NO se debe usar un goto:
if (opcion==1) goto Uno;
if (opcion==2) goto Dos;
if (opcion==3) goto Tres;
goto Otro;
Uno:
{
descuento=10;
goto Fin;
}
Dos:
{
regalo="Cargador de CD";
}
Tres:
{
descuento=5;
goto Fin;
}
Otro:
descuento=0;
Fin:
Console.WriteLine("El descuento es {0} y el regalo {1}",
descuento, regalo);
Este fragmento de código hace lo mismo que el anterior, pero, indudablemente, está muchísimo más enredado, es mucho más difícil de leer, y hemos mandado a paseo a todos los principios de la programación estructurada. Como ves, un mal uso del goto puede hacer que un programa sencillo en principio se convierta en un auténtico desbarajuste. En resumen, no hagáis esto nunca.
Si queréis mi opinión, yo soy partidario de usar el goto sólo en casos muy concretos en los que verdaderamente haga la lectura del código más fácil (como en el ejemplo del switch), aunque, si te digo la verdad, no me hubiera molestado nada en absoluto si el goto hubiera sido suprimido por fin. De todos modos, si no tienes muy claro cuándo es bueno usarlo y cuándo no, lo mejor es no usarlo nunca, sobre todo si vives de esto y quieres seguir haciéndolo. Nadie se lleva las manos a la cabeza si se da un pequeño rodeo para evitar el goto, pero mucha gente se pone extremadamente nerviosa nada más ver uno, aunque esté bien puesto.
RECURSIVIDAD
Bueno, en realidad esto no tiene mucho que ver con las estructuras de control de flujo, pero he decidido ponerlo aquí porque en algunos casos un método recursivo puede reemplazar a un bucle. Además no sabría cómo hacer para colocarlo en otra entrega... y no quería dejarlo sin explicar, aunque sea un poco por encima y a pesar de que esta entrega se alargue un poco más de lo normal.
Bien, vamos al tajo: los métodos recursivos son métodos que se llaman a sí mismos. Sé que puede dar la impresión de que, siendo así, la ejecución no terminaría nunca, pero sin embargo esto no es cierto. Los métodos recursivos han de finalizar la traza en algún punto. Veámoslo con un ejemplo. ¿Recordáis cómo habíamos calculado el factorial mediante un bucle? Pues ahora vamos a hacerlo con un método recursivo. Fíjate bien:
static double Fact(byte num)
{
if (num==0) return 1;
return num*Fact((byte) (num-1)); // Aquí Fact se llama a sí mismo
}
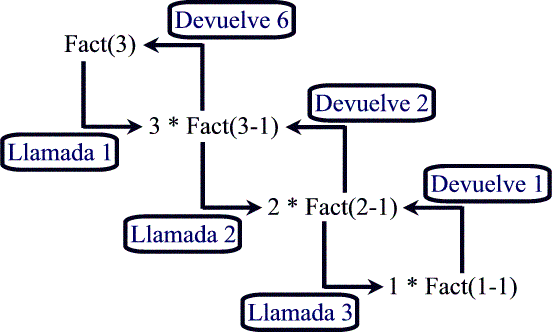
Sí, lo sé, reconozco que es algo confuso, sobre todo para aquellos que estéis empezando. Pero tranquilos, que trataré de explicaros esto con detenimiento. Primero explicaré los motivos por los que uso un tipo double como valor de retorno y un tipo byte para el argumento. Veamos, uso el tipo double porque es el que admite valores más grandes, sí, más que el tipo Decimal, ya que se almacena en memoria de un modo diferente. Por otro lado, uso el tipo byte para el argumento sencillamente porque no tendría sentido usar un tipo que acepte números mayores, ya que pasando de 170 el valor del factorial no cabe ni si quiera en el tipo double. Una vez aclarado esto, veamos cómo funciona. Primero os dibujo la traza, tal y como funciona si se quiere calcular el factorial de 3 (o sea, num vale 3):
Para asegurarme de que comprendes esto bien, observa el código y el gráfico según vas siguiendo la explicación. Cuando en el programa hacemos una llamada al método (Fact(3) en el gráfico) este, evidentemente, comienza su ejecución. Primero comprueba si el argumento que se le ha pasado es igual a cero (revisa el código). Como en este caso el argumento vale 3, el método retornará lo que valga el producto de 3 por el factorial de 3-1, o sea, 3 por el factorial de 2. Claro, para poder retornar esto debe calcular previamente cuánto vale el factorial de 2, por lo se produce la segunda llamada al método Fact. En esta segunda llamada, sucede algo parecido: el argumento vale 2, y como no es igual a cero el método procede a retornar 2 por el factorial de 1 (2 - 1), pero, obviamente, vuelve a suceder igual. Para poder retornar esto ha de calcular previamente cuánto vale el factorial de 1, por lo que se produce la tercera llamada al método Fact, volviendo a darse de nuevo la misma situación: como 1 no es igual a cero, procede a retornar el producto de 1 por el factorial de cero, y de nuevo tiene que calcular cuánto vale el factorial de cero, por lo que se produce una nueva llamada al método Fact. Sin embargo esta vez sí se cumple la condición, es decir, cero es igual a cero, por lo que esta vez el método Fact retorna 1 al método que lo llamó, que era el que tenía que calcular previamente cuánto valía el factorial de 0 y multiplicarlo por 1. Así, la función que tenía que calcular 1*Fact(0) ya sabe que la última parte, es decir, Fact(0), vale 1, por lo que hace el producto y retorna el resultado al método que lo llamó, que era el que tenía que calcular cuánto valía 2 * Fact(1). Como este ya tiene el resultado de Fact(1) (que es, recuerda 1*1), ejecuta el producto, retornando 2 al método que lo llamó, que era el que tenía que calcular cuánto valía 3*Fact(2). Como ahora este método ya sabe que Fact(2) vale 2, ejecuta el producto y retorna el resultado, que es 6, finalizando la traza. Si te das cuenta, un método recursivo va llamándose a sí mismo hasta que se cumple la condición que hace que termine de llamarse, y empieza a retornar valores en el orden inverso a como se fueron haciendo las llamadas.
Bueno, creo que ya está todo dicho por hoy, así que llega el momento de los ejercicios. Sujétate fuerte a la silla, porque esta vez te voy a poner en unos cuantos aprietos.
Antes de nada, no te asustes que es muy fácil. Si no sabes qué es alguna cosa, en las pistas te doy las definiciones de todo. En este ejercicio te voy a pedir que escribas seis métodos, los cuales te detallo a continuación:
El método rFact: debe ser recursivo y retornar el factorial de un número. Ahora bien, no ve vale que copies el que está escrito en esta entrega. A ver si eres capaz de hacerlo con una sola línea de código en lugar de dos.
El método itFact: debe retornar también el factorial de un número, pero esta vez tiene que ser iterativo (o sea, no recursivo).
El método rMCD: debe ser recursivo y retornar el máximo común divisor de dos números. En las pistas te escribo el algoritmo para poder hacerlo.
El método itMCD: también debe retornar el máximo común divisor de dos números, pero esta vez debe ser iterativo (o sea, no recursivo).
El método MCM: debe ser iterativo y retornar el mínimo común múltiplo de dos números.
El método EsPerfecto: debe ser iterativo y retornar true si un número dado es perfecto y false si el número no es perfecto.
Obviamente, todos ellos han de ser static, para que se puedan llamar sin necesidad de instanciar ningún objeto. Escribe también un método Main que pruebe si todos ellos funcionan. Por cierto, trata de hacerlos de modo que sean lo más eficientes posible, esto es, que hagan el menor número de operaciones posible. Hala, al tajo...
Sigue este vínculo para ver las pistas de este ejercicio.
Sigue este vínculo para bajarte los ejemplos de esta entrega.
![]()
![]()
![]()