![]()
Funcionalidad de XmlTextReader
Fecha: d26/Dic/2005 (26-12-05)
|
[Quisiera dedicar este artículo a mi Sra. madre Consuelo Valeriana Paredes Velásquez, a quien agradezco infinitamente por comprenderme y brindarme toda la confianza y el apoyo necesario en mi carrera profesional (Ing. de Sistemas)].
¡lo que debes de saber!
Pues así se dice, debes de leerte este artículo antes de continuar.
Introducción
Pues si no lo sabías en Microsoft .NET Framework, existen dos conjuntos de clases que proveen el manejo de operaciones de lectura y escritura, estas clases son los lectores (XML Readers) y los escritores (XML Writers) de archivos XML. XmlReader es la clase base para los lectores y XmlWriter para la escritura, las cuales brindan toda la interface de programación para realizar dichas operaciones. Por otra parte, las implementaciones de la clase base XmlReader son XmlTextReader, XmlValidatingReader, XmlNodeReader, cuyas funcionalidades estudiaremos en varios artículos por separado. Es así que este artículo se limita a analizar la funcionalidad de la clase XmlTextReader.
XmlReader pertenece es una clase abstracta del namespace System.Xml, y expone la funcionalidad de acceso de sólo avance y de lectura sin almacenamiento en caché. Además, XmlReader define métodos para poblar datos desde un archivo fuente XML y evitando la lectura de los nodos no deseados. Estos métodos de lectura retornan la profundidad (Depth) del nodo XML actual del sub árbol que se está recorriendo o leyendo.
Más información acerca de XmlReader de las propiedades puedes obtenerlo aquí. Muchos de los cuales serán ejemplificadas en este artículo, pero es su obligación investigar más al respecto.
XmlTextReader
La clase XmlTextReader proporciona la funcionalidad de acceso rápido de sólo avance y sólo lectura de archivos XML, previa comprobación de que este archivo xml sea correcto o bien formado, y si se hace uso de un DTD se comprueba si éste tiene el formato correcto, pero no valida utilizando el archivo DTD.
Para procesar un archivo XML debe inicializarse el constructor, como se muestra:
XmlTextReader reader= new XmlTextReader(file);donde file, puede ser la ruta relativa o absoluta de archivo XML a leer.
Hay muchas manera de crear un objeto XmlTextReader, además de ser creados de una variedad de fuentes (archivos de disco, URLs, streams, y text readers). Usted debe especificar en el constructor público la fuente datos, ya le dije, esto puede ser, un stream, un archivo, un TextReader u otra.
usando un TextReader
XmlTextReader reader= new XmlTextReader(new StringReader(xmlData));donde xmlData
string xmlData = @"<?xml version='1.0' encoding='ISO-8859-1'?> <Books > <!--book document xml--> <book> <title>XML Programming</title> <price>48.68</price> </book> <book title='Microsoft visual C# .NET' price='67.29' /> <book> <title>.NET FRAMEWORK </title> <price>73.74</price> </book> </Books>";
usando un archivo localizado en el disco
En este caso, el archivo XML se encuentra en el proyecto actual.
XmlTextReader reader = new XmlTextReader("data.xml");
Acceso a nodos de un archivo XML
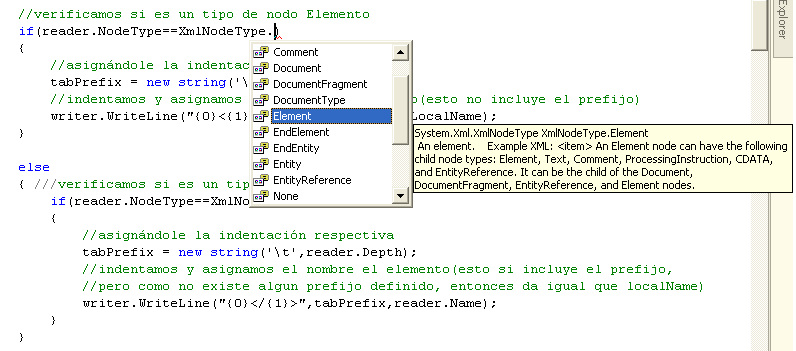
Para analizar el contenido de un archivo XML puede hacerse uso de la enumeración XmlNodeType, de esta manera podemos optar, de acuerdo al tipo de nodo que se está leyendo, por realizar una que otra operación con ella. La siguiente imagen muestra los miembros de esta enumeración, y la manera como puede usarse. Por ahora sólo importa que sepa cuales son estos miembros.
Ahora explicaré, con un ejemplo sencillo, la manera de aprovechar la funcionalidad de XmlNodeType. Por ejemplo si deseáramos imprimir tan sólo las etiquetas, sin el contenido, del fragmento de datos xmlData, debe procederse analizando el tipo de nodo actual que se está leyendo y de acuerdo a esto, realizar uno que otra tarea, como en este caso, sería imprimir las etiquetas (una etiqueta está formada por un nodo o dos nodos, ya sea de abertura y/o cerradura) Para esto haremos uso de la propiedad LocalName que se limita a devolvernos en nombre local de nodo actual (sin prefijo, esto explicaré más adelante), es decir, si el nodo actual es <Books>, entonces esta propiedad devolverá la cadena "Books", pero como queremos imprimir las etiquetas, debemos agregarle los caracteres especiales "<" y ">". En esta caso, <Books>, es una etiqueta de abertura, sólo nos bastó agregarle los caracteres especiales "<" y ">" para imprimirlo en el formato correcto, pero ¿cómo saber cuando agregar "<" y ">" y no "<" y "/>"?, la respuesta es, usando la funcionalidad de XmlNodeType. Primero verificamos el tipo de nodo en la que nos encontramos para luego proceder a agregarle "<" y ">", si es un nodo de tipo Element, o "<" y "/>", en caso de ser un nodo EndElement. Pero como ya le dije, puede usarse LocalName para devolver el nombre, de esta manera, LocalName devolverá "Books" y usted debe agregarle "<" y "/>" programáticamente.En el código siguiente se explica esto y muchas cosas más, revíselo ¡please!.
//documento de datos XML string xmlData = @"<?xml version='1.0' encoding='ISO-8859-1'?> <Books > <!--book document xml--> <book> <title>XML Programming</title> <price>48.68</price> </book> <book title='Microsoft visual C# .NET' price='67.29' /> <book> <title>.NET FRAMEWORK </title> <price>73.74</price> </book> </Books>"; //creamos una instancia de objeto XmlTextReader XmlTextReader reader= new XmlTextReader(new StringReader(xmlData)); //creamos y definimos el ciclo de vida del objeto StringWriter using (StringWriter writer = new StringWriter()) { string indentado=null; //para alamcenar los tabs while(reader.Read()) { //asignándole la indentación respectiva indentado= new string('\t',reader.Depth); //verificamos si es un tipo de nodo Elemento if(reader.NodeType==XmlNodeType.Element) { //si es que tiene atributos if (reader.HasAttributes) writer.WriteLine("{0}<{1}/>",indentado,reader.LocalName); else //indentamos y asignamos el nombre el elemento(esto no incluye el prefijo) writer.WriteLine("{0}<{1}>",indentado,reader.LocalName); } //verificamos si es un tipo de nodo de fin del elemento else if(reader.NodeType==XmlNodeType.EndElement) { //indentamos y asignamos el nombre el elemento(esto si incluye el prefijo, //pero como no existe algun prefijo definido, entonces da igual que localName) writer.WriteLine("{0}</{1}>",indentado,reader.Name); } } //cerramos el reader reader.Close(); //creamos una variable que almacenara los resultados string StringBuffer = writer.ToString(); //imprimimos resultados Console.Write(StringBuffer) ; }La salida será:
Indentando nodos
Algo que habrá notado es que hacemos uso de una propiedad denominada Depth. ¿y para qué?, pues bien para esto. Cuando visualizamos el contenido de un archivo xml usando el Internet Explorer, usted debió percatarse que cada uno de los nodos elementos tienen la indentación correspondiente. Tan sólo fíjese en la indentación, que no viene a ser más que, el espacio de izquierda a derecha hasta llegar al inicio del nodo, o en otras palabras, viene a ser el margen para cada nodo.
Para imprimir el fragmento de datos anterior, debemos simular también, de alguna manera, la indentación adecuada (y esto es lo muestra la primera salida de resultados). Si no usamos la propiedad Depth, los resultados serán impresos así:
creo que esto no se ve bien, además de confundirnos. Y ¿cómo solucionamos esto?, pues bien, gracias a Dios, existe la propiedad Depth devuelve la profundidad del nodo, y este, es un número que va desde 0 para adelante. Entonces, usando el valor de la propiedad Depth crearemos una cadena tabulada (usando \t) que sea múltiplo del valor de Depth. Y luego esto lo concatenamos con "<" + nombre_nodo + ">" (como también, "<" + nombre_nodo + "/>" o "</" + nombre_nodo + ">") quedando como resultado final esto:
y dígame hora, acaso esto no es más presentable y entendible?, pues creo que si.
Mostrando todo el documento XML
La funcionalidad del siguiente código fuente es generar mostrar todo el documento xml. Quedando así:
entonces para esto, manos a la obra, y paso a explicarte.
//creamos el documento XML string xmlData = @"<?xml version='1.0' encoding='ISO-8859-1'?> <Books > <!--book document xml--> <book> <title>XML Programming</title> <price>48.68</price> </book> <book title='Microsoft visual C# .NET' price='67.29' /> <book> <title>.NET FRAMEWORK </title> <price>73.74</price> </book> </Books>"; XmlTextReader reader = new XmlTextReader(new StringReader(xmlData)); //creamos un ojbeto StringWriter. using (System.IO.StringWriter writer = new System.IO.StringWriter()) { while (reader.Read()) { //cadena que almacenará la indentación string indentado= new string('\t', reader.Depth); //evaluando el tipo de nodo switch (reader.NodeType) { //si tipo de nodo es: <?xml version='1.0' encoding='ISO-8859-1'?> case XmlNodeType.XmlDeclaration: //usamos Value para imprimir "xml version='1.0' encoding='ISO-8859-1'" writer.WriteLine("<?{0}?>",reader.Value); break; //if el tipo de nodo es un comentario case XmlNodeType.Comment: writer.WriteLine("{0}<!--{1}-->",indentado,reader.Value); break; //si tipo de nodo es elemento case XmlNodeType.Element: { //y si tiene atributos if (reader.HasAttributes ) { //entonces creamos una cadena "atributos" que guardará //los atributos de este nodo. string atributos=null; for (int i = 0; i < reader.AttributeCount; i++) { //nos movemos para realizar la lectura del atrbiuto de acuerdo al índice. reader.MoveToAttribute(i); //una vez que estamos ubicados en la posición correcta, //leemos el nombre del atributo, como también el valor. atributos+= " " + reader.Name + "='"+ reader.Value +"'" ; } //despues de haber leido los atributos del elemento... //moveremos el puntero al elemento. reader.MoveToElement(); //visuali writer.WriteLine("{0}<{1} {2}/>",indentado,reader.LocalName,atributos); } else { //si la profundidad del nodo es diferente a 2 if (reader.Depth!=2) writer.WriteLine("{0}<{1}>",indentado,reader.LocalName); else writer.Write("{0}<{1}>",indentado,reader.LocalName); } }break; //if el tipo de nodo es contenido. case XmlNodeType.Text: //imprimimos el contenido. writer.Write(reader.Value); break; //si el tipo de nodo es un elemento final o de cierre. case XmlNodeType.EndElement: //y además, averiguamos si es el que Depth es 2 entonces //no le agregamos la indentación, imprimiendo de esta manera: //<title>XML Programming</title> en vez de <title>XML Programming </title> if (reader.Depth==2) writer.WriteLine("</{0}>",reader.LocalName); else //con indentación tabPrefix writer.WriteLine("{0}</{1}>",indentado,reader.LocalName); break; } } //cerramos el reader reader.Close(); //mostrar los resultados. Console.Write(writer.ToString()); }
XmlReader y los namespaces
Ahora analizaremos otro ejemplo, un poco más complicado. Nos encontramos en una situación en donde manejaremos espacios de nombres. Los espacios de nombres sirven para calificar el contenido XML. Observe ahora el contenido del documento XML, y verá que se ha definido el prefijo "mb" que hace referencia tan sólo a todos los libros de Microsoft .NET, pero aún no se ha definido, en el documento, el espacio de nombres correspondiente, sin embargo, usamos una instancia del objeto XmlNamespaceManager, programáticamente, para agregar este espacio de nombres "MicrosoftBooks" ("urn" define el espacio de nombre) que servirá como información de contexto para el análisis del documento.
La cosa funciona así. El objeto _nametable es necesario crearlo porque es aquí donde se almacenara los nombres que manejara el objeto ManajadorDeEspacioDeNombres. Luego agregamos el namespace MicrosoftBooks a la tabla de nombres que se encuentra dentro de ManajadorDeEspacioDeNombres. Todo lo realizado hasta el momento necesita ser encapsulado con un sólo paquete de información que será útil para la lectura de los datos xml, es así que, crearemos un objeto XmlParserManager nombrado information_context que encapsulará dicha información, la cual se embeberá en el constructor de objeto XmlTextReader denominado reader. Esta información muy útil para el reader, pues de esta manera, se hace saber al reader cuales son las reglas de lectura de los datos, y cuales namespaces debe tener en cuenta para dicha lectura. Los resultados que se pretende obtener es la siguiente:
En el siguiente código fuente se hace uso de la propiedad Prefix para el objeto reader. Es esta propiedad la encargada de devolvernos el prefijo que hace referencia al espacio de nombres MicrosoftBooks, es decir, Prefix devuelve como valor la cadena "mb". Cuando imprimimos el nombre de un nodo con prefijo haciendo uso de la propiedad LocalName, el LocalName contendrá el nombre sin prefijo, y esto lo hace diferente a la propiedad Name que devuelve el nombre incluyendo el prefijo. Por ejemplo, para el nodo:
<mb:book title='Microsoft visual C# .NET' price='67.29' />la propiedad LocalName, devuelve: book
la propiedad Name devuelve: mb:book
Entonces, usaremos la prpiedad Prefix para detectar que nodos contienen libros de Microsoft .net, la cual fue "marcada" con el prefijo "mb" que hace referencia al espacio de nombre "MicrosoftBooks". De esta manera sabremos cuando usar las propiedades LocalName y Name. Espero haya entendido, o mejor dicho, espero haber sido lo suficientemente claro en la explicación. Ahora tengo algo de hambre y debo ir al kiosko de la esquina, a ver que me traigo para saciarme.
Dejo el código fuente para que usted lo revise.
//creamos una instancia del objeto XmlNamespaceManager //para manejar los espacios de nombres xml. //creamos una instancia del objeto NameTable que guardará los nombres NameTable _nametable = new NameTable(); //creamos una instancia del objeto XmlNamesapceManager que //manejará los nombres que se encuentran en la tabla de nombres _nt XmlNamespaceManager ManejadorDeEspacioDeNombres = new XmlNamespaceManager(_nametable); //le agregamos un namespace y un nombre que pertenecerá a este. ManejadorDeEspacioDeNombres.AddNamespace("mb","urn:MicrosoftBooks"); //también es necesario crear una instancia del objeto XmlParserContext, //la cual define la información de contexto XmlParserContext information_context = new XmlParserContext(_nametable, ManejadorDeEspacioDeNombres,"en-US", XmlSpace.None); //creamos el documento XML string xmlData = @"<?xml version='1.0' encoding='ISO-8859-1'?> <Books > <!--book document xml--> <book> <title>XML Programming</title> <price>48.68</price> </book> <mb:book title='Microsoft visual C# .NET' price='67.29' /> <mb:book> <title>.NET FRAMEWORK </title> <price>73.74</price> </mb:book> </Books>"; //creamos el lector del documento XmlTextReader reader = new XmlTextReader(xmlData,XmlNodeType.Element,information_context); //imprimimos cada uno de los nodos. using (System.IO.StringWriter writer = new System.IO.StringWriter()) { //leyendo... while (reader.Read()) { //definiendo el indentado string indentado= new string('\t', reader.Depth); //evaluando el tipo de nodo switch (reader.NodeType) { //tipo de nodo declaración del documento xml. case XmlNodeType.XmlDeclaration: //imprimi valor writer.WriteLine("<?{0}?>",reader.Value); break; //tipo de nodo elemento case XmlNodeType.Element: { //si existen atributos. if (reader.HasAttributes) { //cadena que guardará temporalmente los atributos leidos string atributos=null; //leyendo cada uno de los atributos for (int i = 0; i < reader.AttributeCount; i++) { //usamos el indice para movernos por cada atributo. reader.MoveToAttribute(i); //imprimimos, tanto el nombre del atributo, como el valor de este. atributos+= " " + reader.Name + "='"+ reader.Value +"'" ; } //regresamos el puntero al inicio del nodo //donde se estaba leyendo los atributos. reader.MoveToElement(); //evaluamos la profundidad del nodo. if (reader.Depth!=2) { //si es que el nodo tiene un prefijo if(reader.Prefix!=string.Empty) //imprimimos. writer.WriteLine("{0}<{1}:{2}{3}/>",indentado,
reader.Prefix,reader.LocalName,atributos); else //imprimos pero sin prefijo writer.WriteLine("{0}<{1}{2}/>",indentado,reader.LocalName,atributos); } //si la profundidad es igual a 2 else { writer.Write("{0}<{1}{2}/>",indentado,reader.LocalName,atributos); } } //si es que no tiene atributos. else { //de nuevo con este rollo de la profundidad. if (reader.Depth!=2) { //esto es igual a lo de arriba que ya te expliqué. if(reader.Prefix!=string.Empty) //imprimimos writer.WriteLine("{0}<{1}:{2}>",indentado,reader.Prefix,reader.LocalName); else //y dale! con la misma pasta, je, je, je... writer.WriteLine("{0}<{1}>",indentado,reader.Name); } //en caso de que la profundidad del nodo sea igual a 2. else { writer.Write("{0}<{1}>",indentado, reader.Name); } } }break; //ya sabéis para que sirve esto... case XmlNodeType.Comment: writer.WriteLine("{0}<!--{1}-->",indentado,reader.Value); break; //y esto también ya sabéis. case XmlNodeType.Text: writer.Write(reader.Value); break; //y esto más aún... esto en verdad, ya me aburre.. case XmlNodeType.EndElement: if (reader.Depth!=2) { if (reader.Prefix!=String.Empty) writer.WriteLine("{0}</{1}:{2}>",indentado,reader.Prefix, reader.LocalName); else writer.WriteLine("{0}</{1}>",indentado, reader.Name); } else { writer.WriteLine("{0}</{1}>",reader.Prefix, reader.Name); } break; } } //cerramos el reader reader.Close(); Console.Write(writer.ToString()); }He terminado de explicar esta primera parte. Nos vemos en la siguiente entrega (si es que no me distraigo en otras cosillas, je, je, je).
pero antes me gustaría que me respondieras algo: te dedicas a programar, ¿por diversión o por dinero?. Envíame tu respuesta al correo que adjunto de indico más arriba.
Microsoft Certified Professional
Estudiante Ing. de Sistemas
Universidad Nacional de TrujilloSaludos desde Trujillo - Perú
Por favor, califica este artículo en Panoramabox, así me animarás a continuar colaborando contigo.