![]()
|
Entrenando y simulando una red neuronal en C#
Fecha: 01/Jul/2004
Nota del Guille:
|
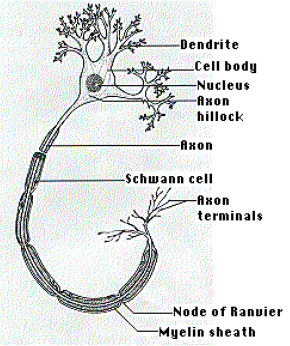
Figura 1(a) – Red Neuronal en el Cuerpo Humano
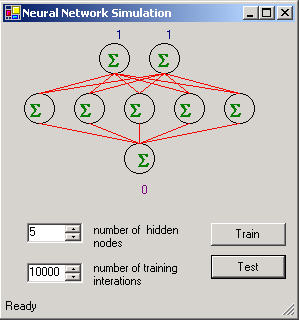
Figura 1(b) – Red Neural XOR simulada en .NET
Introducción
Aunque las computadoras son sistemas digitales que trabajan en 1 y 0, nuestras mentes funcionan a un bit de diferencia. Como los científicos han explorado el funcionamiento de los cerebros humanos, encontraron que consisten en una red de neuronas que se comunican con cada una a través de señales eléctricas y químicas, y así forman nuestros pensamientos. Estas neuronas se encienden basándose en la fuerza o en la debilidad de las señales que pasan por ellas. Las señales no son 1 y 0, pero niveles análogos con una amplia gama del potencial. ¿Como aprendemos?, las neuronas en nuestro cerebro ajustarán el potencial entre estas conexiones, y desarrollará los umbrales y las trayectorias que harán cumplir las asociaciones que recibimos como entrada con nuestros sentidos. Por lo tanto, de una manera, nuestros cerebros son mas o menos una computadora análoga adaptante de paralelo-proceso orgánica de 3 libras.
Simulando una red de los nervios en la computadora podemos capturar una de las capacidades más grandes de nuestro cerebro, la capacidad de reconocer patrones. Las redes de los nervios se utilizan hoy sobre todo para el reconocimiento de patrón en usos tales como reconocimiento, predicción común, y análisis biométrico.
En este artículo exploraremos un algoritmo bien conocido de la IA para modelar el entrenamiento de las redes de los nervios llamadas “Propagación hacia Atrás”. Utilizaremos este algoritmo para entrenar a una red de los nervios para realizar un XOR (exclusiva o) en sus dos entradas y para entrenara un detector de número primero en sus diez entradas.
Algoritmo de la Red Neural
Una red Neural es simulada en una computadora creando los nodos cargados que se interconectan el uno al otro con diversas capas: la capa de la entrada, algunas capas ocultas, y una capa de la salida. Una señal pasa a un nodo de entrada en la capa de la entrada y luego es multiplicada por los pesos en todas las conexiones a los nodos en la capa siguiente y sumada para formar un valor de la activación. Este valor se pasa con lo qué se conoce como “función delta” que altera la suma cargada a un valor no lineal y simula algo cómo una señal neuronal en el cerebro. El nuevo valor de la activación se pasa encendido a la capa siguiente y es ajustado otra vez por la suma de los valores cargados. Este proceso continúa hasta que el valor ajustado alcanza la capa de la salida donde se lee.
Entrenando a la Red
En la “Propagación hacia Atrás”, una red neural es entrenada comparando el valor final que ocurre en la salida de la red, al valor deseado de la salida y que alimenta el error a través de la red.
Este error se usa para ajustar los pesos en los nodos de los nervios, si se envía el respaldo del error con los nodos para muchas iteraciones esperanzadamente los pesos convergerán eventualmente a los valores que darán la salida real de la red. Hay siempre la posibilidad que los pesos pueden no converger, o los pesos convergen a un cierto mínimo local y no proporcione una solución óptima. Ajustando algunos de los parámetros de la red (número de capas ocultadas, parámetros del umbral, número de nodos ocultos), usted puede mejorar la exactitud de su red.
Una vez que se entrene una red de los nervios, usted no puede necesitar siempre entrenarla otra vez. Usted puede apenas utilizar los pesos resueltos finales para todos sus datos. Si, sin embargo, los datos de entrada en su ambiente están cambiando constantemente (por ejemplo en las predicciones comunes), usted encontrará probablemente eso periódicamente, usted puede necesitar enseñar/aprender habilidades nuevas a la red neural. Otra cosa a la nota sobre el entrenamiento, la salida es buena si la entrada es buena. Usted debe utilizar los datos que cubren la amplia gama de posibilidades que usted espera como entradas en la red. También, (pues no necesito probablemente mencionar), la salida deseada debe ser exacta. Como dicen en la industria del software “Basura Entra = Basura Sale”
Propagación hacia Atrás
Una de las mejores explicaciones para éste algoritmo que encontré está en un artículo escrito por “Christos Stergiou y Dimitrios Siganos” titulado “Neural Networks” (http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/cs11/report.html).
Describiré brevemente las matemáticas y los pasos del algoritmo. El primer paso es el paso delantero usado para determinar los niveles de la activación de las neuronas. El paso delantero es el mismo paso usado para hacer funcionar la red neural después de que se entrene. En nuestro ejemplo tenemos solamente tres capas, la de entrada, ocultado, y salida. Primero calcularemos los niveles de la activación de la capa ocultada. Esto es logrado por valores de la entrada por la matriz del peso entre la capa de la entrada y la capa ocultada y después el funcionamiento de los resultados con una función sigmoidea:
1. Lhidden = sigmoid ( Linput * [Weightsinput-hidden])
Se demuestra la función sigmoidea debajo de la cual acerca a 1 para los valores grandes de x; y a 0 para los valores muy pequeños de x. Esto tras todas las activaciones a una aproximación no linear de la neurona:
sigmoid (x) =
1
1 + e-x
El paso siguiente en la activación delantera es computar las activaciones de la capa de la salida de la capa ocultada (en el paso1) y la matriz sináptica del peso que tiende un puente sobre la capa ocultada a la capa de la salida. Entonces nosotros finalmente tenemos que aplicar el sigmoideo a la matriz del producto que resulta.
2. Loutput = sigmoid ( Lhidden * [Weightshidden-output])
Loutput (o los valores de la capa de la salida) contiene los resultados de alimentar nuestra entrada inicial en la red Neural.
Una vez que hayamos calculado las activaciones para nuestras neuronas, necesitamos calcular el error que resulta entre la salida real y la salida deseada. Este error se retroactúa a través de la red de los nervios y se utiliza para ajustar los pesos para adaptarse a un modelo más exacto de nuestros datos. El primer paso es computar el error de la capa de la salida:
3. Eoutput = Loutput * (1- Loutput ) * (Loutput - Ldesired)
Ahora alimentamos este error en la capa ocultada para computar el error ocultado de la capa:
4. Ehidden = Lhidden * (1 - Lhidden ) * [Weightshidden-output ] * Eoutput
Necesitamos después ajustar la matriz del peso entre el capa ocultada y la capa de la salida para adaptar nuestra red y compensar el error. Para ajustar los pesos agregaremos dos factores constantes a nuestro algoritmo. El primer factor es una tarifa que aprende (LR), cuál ajusta cuánto afecta el error computado del cambio del peso en un solo ciclo a través de la red neural. El segundo factor es un factor del ímpetu (frecuencia intermedia) usado conjuntamente con el cambio anterior del peso para afectar el cambio final en el ciclo actual a través de la red. El ímpetu puede ayudar a menudo a una red a entrenar un poco más rápido.
5. [Weightshidden-output ] = [Weightshidden-output ] + D[Weightshidden-output ]
Donde:
D[Weightshidden-output ] = (LR) * Lhidden * Eoutput + (MF) * D[Weightshidden-output (previous)]
Finalmente necesitamos ajustar los pesos para que haya la capa de la entrada de la misma manera:
6. [Weightsinput-hidden] =[Weightsinput-hidden] + D[Weightsinput-hidden]
Donde:
D[Weightsinput-hidden] = (LR) * Linput * Ehidden + (MF) * D[Weightsinput-hidden(previous)]
Después de que se ajusten los pesos, los pasos 1 a 6 se repiten para el sistema siguiente de entrada y de valores deseados de la salida. El sistema entero de datos se va de una vez, y repetimos el algoritmo para todos los datos otra vez. Este proceso continúa hasta que converge la red o hasta que elegimos detener la iteración de los datos.
Codificación del Algoritmo:
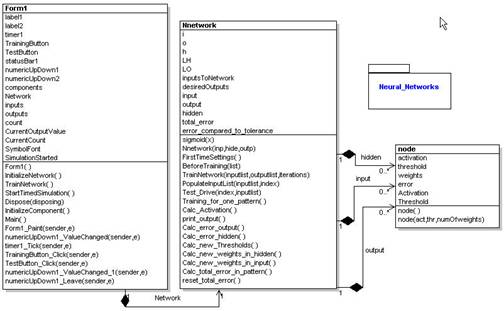
Acabo de alterar el código levemente para tener en cuenta el entrenamiento repetido y lo he hecho un poco más fácil. Debajo está el diagrama de UML que describe la red neural.
La red neural consiste en dos clases Nnetwork y Node. Un nodo contiene la matriz de los pesos de la neurona así como el valor de la activación. El Nnetwork (red de los nervios) funciona todos los pasos de la propagación usando el arsenal de nodos contenidos en cada capa (entrada, ocultado, y salida) según lo visto de las relaciones agregadas en el diagrama de UML.
Figura 2 – UML de la Red Neural
Pasos de la Simulación:
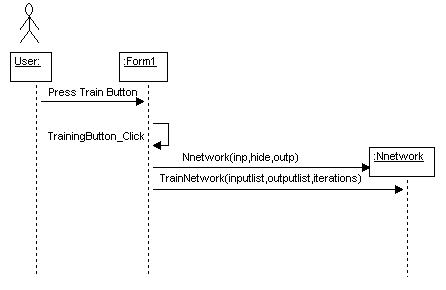
Cuando el usuario presiona el botón de Entrenamiento en el cuadro 1, se construye la red de los nervios y se llama al método de TrainNetwork.
Figura 3 – Entrenamiento de la Red
El método TrainNetwork llama en varias ocasiones al método Training_for_one_pattern cada vez para todas las entradas y sus correspondientes salidas para las N iteraciones.
El valor de iteraciones se pasa en la función de TrainNetwork, este valor es controlado por el usuario. A continuación se muestra el código del método de TrainNetwork:
Lista 1 - Entrenar a la Red
public void TrainNetwork(double[,] inputlist, double[,] outputlist, int iterations)
{
// Arreglos que contienen las entradas y Salidas
inputsToNetwork = new double[this.i];
desiredOutputs = new double[this.o];
int outputlistSampleLength = outputlist.GetUpperBound(0) + 1;
int outputlistLength = outputlist.GetUpperBound(1) + 1;
int inputlistLength = inputlist.GetUpperBound(1) + 1;
for (int i = 0; i < iterations; i++)
{
for (int sampleindex = 0; sampleindex < outputlistSampleLength; sampleindex++)
{
for (int j = 0; j < inputlistLength; j++)
{
inputsToNetwork[j] = inputlist[sampleindex, j];
}
for (int k = 0; k < outputlistLength; k++)
{
desiredOutputs[k] = outputlist[sampleindex, k];
}
// Entrenar para el siguiente set de E/S
Training_for_one_pattern();
}
}
}
Training_for_one_pattern llama a todos los métodos que se explicaron en los pasos 1-6 de nuestro algoritmo de propagación. A continuación se muestra su contenido:
Lista 2 - Método Training_for_one_pattern
public void Training_for_one_pattern()
{
// Calcula la Activación para todas las Capas (pasos 1 y 2)
Calc_Activation();
// Calcula el error en la capa de salida (paso 3)
Calc_error_output();// Calcula el error en la capa de ocultación (paso 4)
Calc_error_hidden();
// Calcula nuevos pesos in la capa oculta ajustando con el error de la capa de salida (paso 5)
Calc_new_weights_in_hidden();// Calcula nuevos pesos en la capa de entrada ajustando con el error de la c. oculta (paso 6)
Calc_new_weights_in_input();
}Ejecutando la Red:
Recuerde que los primeros pasos del algoritmo son los mismos pasos que utilizamos para hacer funcionar a nuestra red después de que ésta se entrene. El método de Calc_Activation de nuestra clase pone el proceso en ejecución. En la primera parte del método, cada nodo de la capa de entrada es multiplicado por los pesos entre la entrada y la capa ocultada y un sigmoideo se aplica para obtener el valor de activación del nodo ocultado. En la segunda parte, cada nodo de la capa ocultada es multiplicado por los pesos entre la capa oculta y la capa de la salida, luego un sigmoideo se aplica para obtener el valor de la activación del nodo de la salida
Lista 3 - Método Calc_Activation:
private void Calc_Activation()
{
// Iteración entre el conjunto de activaciones en la capa oculta.
int ch=0;
while(ch<this.h)
{
for(int ci=0 ; ci<this.i ; ci++)
hidden[ch].Activation += inputsToNetwork[ci] * input[ci].weights[ch];
ch++;
}
// calcular la salida de la capa oculta
for(int x=0 ; x<this.h ; x++)
{
hidden[x].Activation = sigmoid(hidden[x].Activation );
}
// Iteración entre el conjunto de activaciones en la capa de salida.
int co=0;
while(co<this.o)
{
for(int chi=0 ; chi<this.h ; chi++)
output[co].Activation += hidden[chi].Activation * hidden[chi].weights[co];
co++;
}
// Calcular la salida de la capa de Salida
for(int x=0 ; x<this.o ; x++)
{
output[x].Activation = sigmoid(output[x].Activation );
}
}
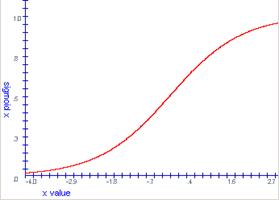
La red utiliza System.Math para poner la función en ejecución sigmoidea demostrada en el listado 4. Esta función forma una curva (adyacente al código en el cuadro 4). La curva sigmoidea permite que los valores fuera de un nodo actúen como una neurona. Para valores más grandes de la entrada en la neurona, la neurona se satura y alcanza un límite del valor. Para valores más pequeños de la entrada de la neurona, la neurona es menos sensible y tiende a permanecer en un valor cerca de cero. Para los valores de la entrada a partir del -0.5 a 0.5, la curva parece ser casi linear dando un rango proporcional entre los datos entrantes y salientes.
Lista 4 - Método Sigmoideo
private double sigmoid(double x)
{
return 1/(1+Math.Exp(-x));
}
Figura 4 – Curva Sigmoidea para valores en X
Entrenando a la Red Neural XOR
Porque la red neural puede manejar mapeos lineares o no lineares, la “o exclusiva” (XOR) es un buen experimento simple para probar, bien la red aprende del patrón. Los datos del arsenal indicados en el listado 5 se alimentan en la red para entrenar a los pesos. La entrada consiste en todas las combinaciones de los datos de XOR para un sistema de 2 Entradas. Las salidas representan todos los resultados posibles. Porque esto es un sistema cerrado bastante pequeño, la red no es muy complejo (véase la figura 1). La red se entrena rápidamente después de 5000-10000 iteraciones. Con tan pocos nodos, 10000 iteraciones toman mas o menos un segundo en un Pentium IV.
Lista 5 – XOR Entradas y Salidas
// Entradas y Salidas
double[,] inputs = {{0,0}, {0,1}, {1, 0}, {1,1}};
double[,] outputs = {{0}, {1}, {1}, {0}};
Entrenando a la RED para reconocimiento de números Primos
Porque éste es un ejemplo tan trivial, Decidí hechar una ojeada un ejemplo poco más complejo: entrenamiento de la red para reconocer números primos entre 0 y 1000. Los datos para este ejemplo serán incorporados en formato binario. Cada número primo a partir de la 0-1000 (los 168 de ellos), se entran en la entrada así como todos los números no-primos de (0-1000). La salida deseada es "1" si el número es primo y "0" si el número no es primo. El número de los nodos de la entrada necesita corresponder al número de dígitos binarios en el número más grande incorporado. Puesto que el número más alto es 1000, el equivalente binario es alrededor 210 = 1024. Por lo tanto necesitamos 10 Entradas
Ingresando los datos Binarios
Para alimentar los datos binarios en la red, construimos una lista de todos los números primos como números enteros a partir de la 1 a 1000. Construimos después los datos binarios de la entrada y de la salida del número primo dinámicamente según lo demostrado en el listado 6
Lista 6 – Genración de Numeros Primos
void InitializeNetwork()
{
// Rellenamos el vector con numero primos y no primos
for (int i = 0; i < inputs.GetLength(0); i++)
{
int num = i;
int mask = 0x200;
for (int j = 0; j < 10; j++)
{
if ((num & mask) > 0) inputs[i, j] = 1;
else inputs[i, j] = 0;
mask = mask >> 1;
}
// Verificar si el Numero es Primo
// si no lo es, establecer la salida a 1
// caso contrario a 0
if (Array.BinarySearch(primes, i) >= 0)
{
// Se ha encontrado un Primo
outputs[i,0] = 1;
}
else
{
outputs[i,0] = 0;
}
}
}
Añadiendo Caracteristicas y Ajustes en la Red
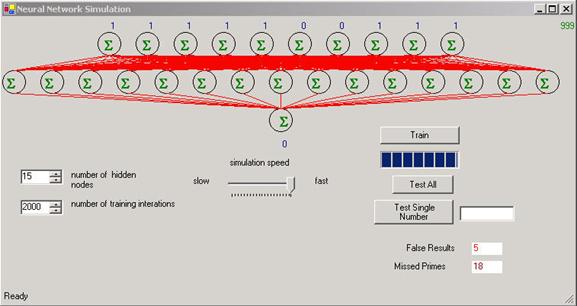
La red parece trabajar mejor cuando el número de nodos ocultados en la capa oculta es mayor que el número de los nodos de la entrada. Por lo tanto elegimos quince nodos entrados en la capa oculta. La capa de salida tiene solamente un nodo que corresponde a un determinándo si o no. La figura 5 demuestra la forma de Windows que exhibe la red neural. Nota se ha agregado un poco más funcionalidad al formulario incluyendo estadísticas sobre la red y control en la velocidad de la simulación.
Resultados Finales
La Figura 5 muestra la forma de Windows después de que la red se haya entrenado ya en 2000 iteraciones de todos los números a partir de la 1-1000. Después de entrenarla, fijamos la simulación a la velocidad más alta y pulsamos el boton de Prueba. Como la simulación vuela con 1000 números binarios, la estadística se recoge para considerar si la red contiene errores. Hay dos clases de errores que puedan ocurrir en la salida: números que la red considera prima, pero son realmente compuestos (no-primo) y los números que la red considera compuesto pero son realmente primos. Ambas estadísticas se recogen en la esquina inferior derecha de la forma. Después de jugar con la red, Encontré que al aumentar el número de nodos en la capa oculta y el aumento del número de iteraciones disminuyó el error. Por supuesto ambos ajustes vienen con la pena de la cantidad de tiempo que toma para entrenar a la red (algunos minutos para 2000 iteraciones).
Figura 5 – Detector de Primos despues de entrenarla con 1000 números
Conclusión
La red neural, aunque es lenta de entrenar, es la mejor manera de lograr gran alcance en el reconocimiento de patrones de datos conociendo las entradas y las salidas. Por ejemplo usted puede utilizar la red para reconocer cualquier cosa de sonidos o Caracteres (OCR). Un proyecto que usted podría intentar sería crear un control de tinta en la forma de Windows que permite que usted dibuje caracteres y después que traze las regiones del pixel de los caracteres a la entrada de la red. La salida podía consistir en todos los caracteres ASCII posibles. Otro proyecto puede ser tomar un sistema de clips de los sonidos y alimentarlos en la entrada. Entonces la salida podía consistir en los números que corresponde a cada uno de los diversos clips. Por supuesto usted necesitaría reducir grandemente el número de muestras en cada clip. De todas formas existen diversas aplicaciones donde se puede trabajar con redes neurales, y yo espero que hayan aprendido algo de la sinapsis.
Autor:
Jose Manuel Lopez Izquierdo, Microsoft Most Value Professional (MVP Asp/Asp.Net), Microsoft Certified Professional .Net, Director de Investigación y Proyectos de la Universidad Catolica de Cuenca – Azogues, Jefe de Sistemas de la Dirección Provincial de Salud del Cañar, Catedratico de Inteligencia Artificial en la Universidad Catolica, Director de sección de Sincronet, vivo en Ecuador.

El código de ejemplo (C# 2003): jlopezi_RedNeural.zip (14.2 KB)